

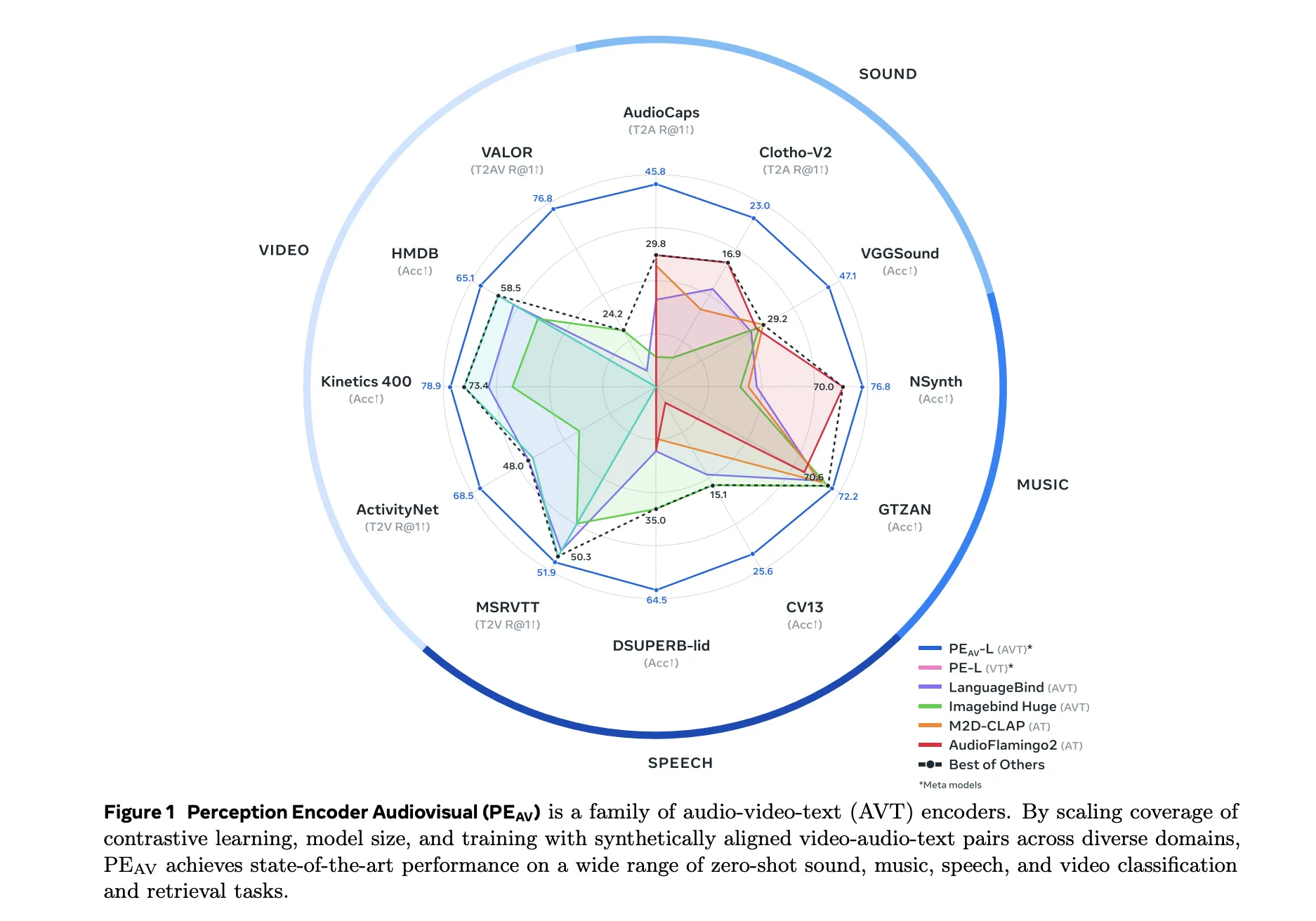
Meta just open-sourced PE-AV, their audiovisual encoder trained on ~100M audio-video pairs that maps audio, video, and text into a unified embedding space. This is the backbone behind SAM Audio and their large-scale multimodal retrieval systems. Really interesting to see contrastive training at this scale for joint AV understanding
0 Commentarii
0 Distribuiri
18 Views
