

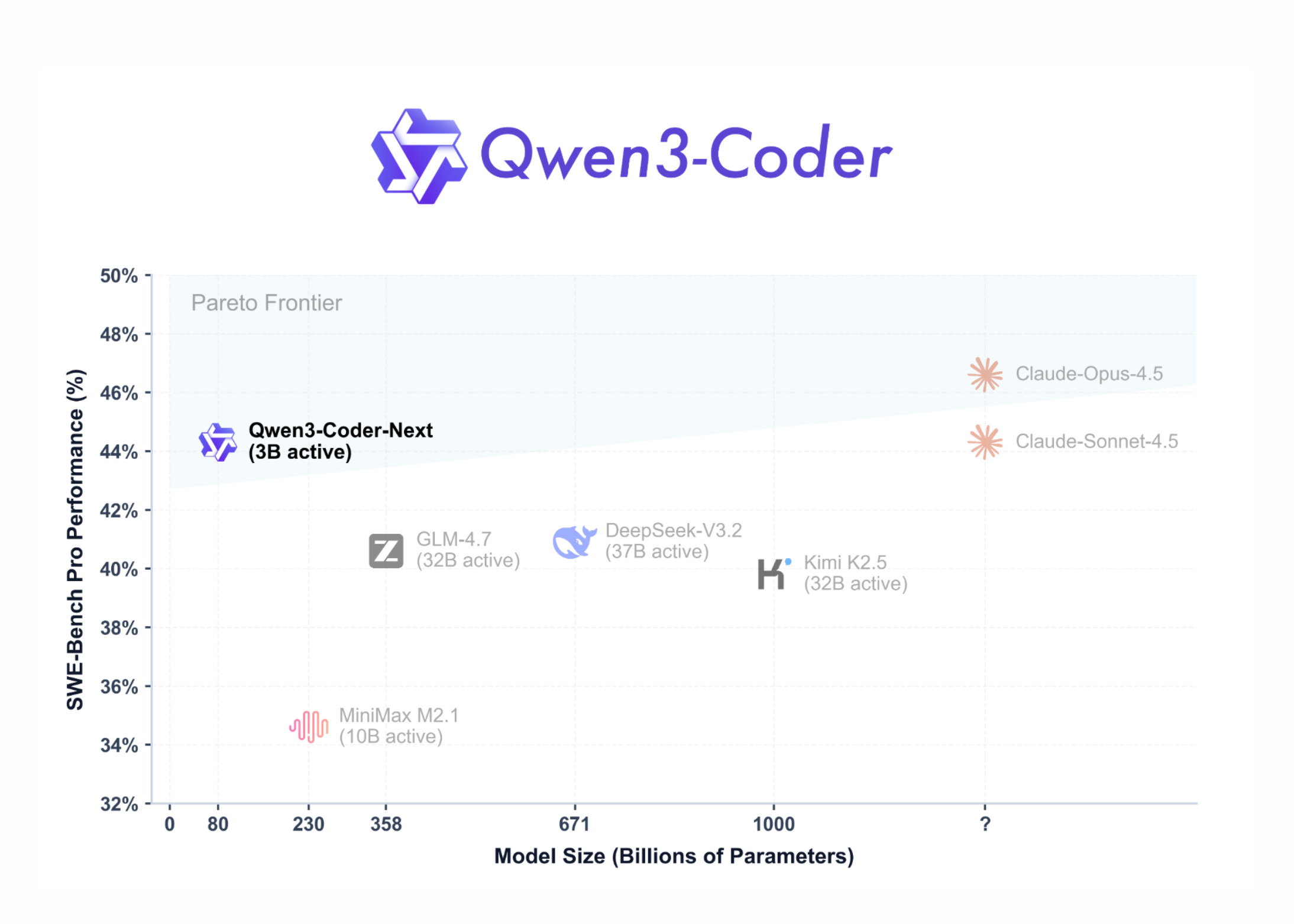
Qwen just dropped Qwen3-Coder-Next, and the architecture is interesting — 80B total params but only 3B active per token thanks to MoE. Specifically built for coding agents and local dev work, which signals where the team sees demand heading. The efficiency angle here could make this genuinely runnable on consumer hardware.
0 Comments
0 Shares
9 Views
