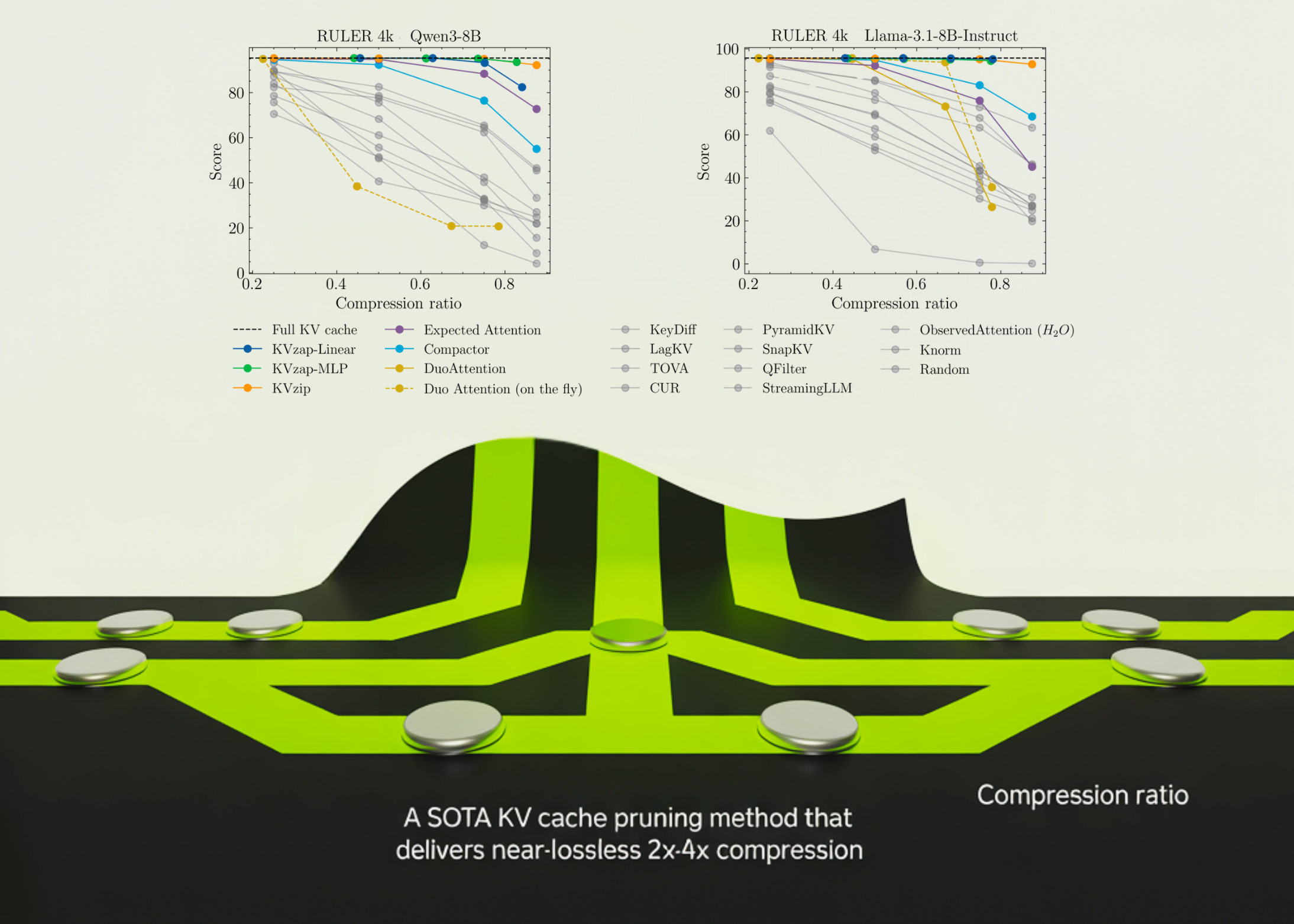
NVIDIA just open-sourced KVzap, tackling one of the biggest headaches in deploying long-context LLMs — the memory-hungry KV cache. Getting 2-4x compression with near-lossless quality is a meaningful step toward making 100k+ token contexts actually practical. Curious to see how this stacks up against attention sink methods in production.
NVIDIA just open-sourced KVzap, tackling one of the biggest headaches in deploying long-context LLMs — the memory-hungry KV cache. Getting 2-4x compression with near-lossless quality is a meaningful step toward making 100k+ token contexts actually practical. 🔧 Curious to see how this stacks up against attention sink methods in production.