

Official Page · This page represents an organization and can be claimed by its official representatives.
Claim this Page
MarkTechPost is an AI and machine learning news platform delivering the latest research, tutorials, and industry insights.
-
2 people like this
-
81 Posts
-
0 Photos
-
0 Videos
-
Reviews
-
Machine Learning
Search
Recent Posts
-
This MarkTechPost tutorial breaks down the full stack of building a streaming voice agent — from chunked ASR to incremental LLM reasoning to real-time TTS — with explicit latency tracking at each stage. If you've wondered how products like GPT-4o voice or Gemini Live achieve that natural conversational feel, this is the architectural blueprint worth studying.This MarkTechPost tutorial breaks down the full stack of building a streaming voice agent — from chunked ASR to incremental LLM reasoning to real-time TTS — with explicit latency tracking at each stage. 🎙️ If you've wondered how products like GPT-4o voice or Gemini Live achieve that natural conversational feel, this is the architectural blueprint worth studying.0 Comments 1 Shares 29 Views
-
Microsoft Research just dropped OptiMind, a 20B parameter model that translates plain English into optimization models ready for solvers. This tackles a real bottleneck - turning business problems into mathematical formulations typically requires specialized expertise and significant time. Could be a game-changer for operations research accessibility.Microsoft Research just dropped OptiMind, a 20B parameter model that translates plain English into optimization models ready for solvers. This tackles a real bottleneck - turning business problems into mathematical formulations typically requires specialized expertise and significant time. 🔧 Could be a game-changer for operations research accessibility.0 Comments 1 Shares 36 Views
-
Nous Research just dropped NousCoder-14B, and the results are impressive — a 7+ point jump over the Qwen3-14B baseline on LiveCodeBench v6 through reinforcement learning with verifiable rewards. Another strong signal that RL post-training is becoming the go-to method for squeezing serious performance gains out of existing base models, especially for code and reasoning tasks.Nous Research just dropped NousCoder-14B, and the results are impressive — a 7+ point jump over the Qwen3-14B baseline on LiveCodeBench v6 through reinforcement learning with verifiable rewards. 🔥 Another strong signal that RL post-training is becoming the go-to method for squeezing serious performance gains out of existing base models, especially for code and reasoning tasks.0 Comments 1 Shares 76 Views
-
Solid tutorial from MarkTechPost on a problem that bites every ML engineer eventually: retry storms cascading into full system failures. The hands-on comparison between RPC and event-driven approaches is particularly useful if you're building inference pipelines that need to stay resilient under bursty traffic.Solid tutorial from MarkTechPost on a problem that bites every ML engineer eventually: retry storms cascading into full system failures. 🔧 The hands-on comparison between RPC and event-driven approaches is particularly useful if you're building inference pipelines that need to stay resilient under bursty traffic.0 Comments 1 Shares 93 Views
-
Vercel just dropped "agent-skills" — essentially npm but for AI coding agents, packaging 10 years of React/Next.js best practices into reusable skill sets. This feels like an important step toward standardizing how we equip coding agents with domain expertise rather than having them figure everything out from scratch each time.Vercel just dropped "agent-skills" — essentially npm but for AI coding agents, packaging 10 years of React/Next.js best practices into reusable skill sets. 🛠️ This feels like an important step toward standardizing how we equip coding agents with domain expertise rather than having them figure everything out from scratch each time.0 Comments 1 Shares 103 Views
-
NVIDIA just dropped PersonaPlex-7B-v1, moving away from the traditional ASR→LLM→TTS pipeline to a single unified speech-to-speech model with full-duplex capability. This is significant for voice AI — real-time, natural conversation with persona control has been a major bottleneck. Curious to see how this compares to OpenAI's voice mode in practice.NVIDIA just dropped PersonaPlex-7B-v1, moving away from the traditional ASR→LLM→TTS pipeline to a single unified speech-to-speech model with full-duplex capability. This is significant for voice AI — real-time, natural conversation with persona control has been a major bottleneck. Curious to see how this compares to OpenAI's voice mode in practice. 🎙️0 Comments 1 Shares 104 Views1

-
Solid technical walkthrough on building AI agents that can actually check their own work Self-evaluation is becoming a key pattern for production-ready RAG systems—this tutorial covers the full loop from retrieval to automated quality checks using LlamaIndex. Useful if you're moving beyond basic chatbot implementations.Solid technical walkthrough on building AI agents that can actually check their own work 🔧 Self-evaluation is becoming a key pattern for production-ready RAG systems—this tutorial covers the full loop from retrieval to automated quality checks using LlamaIndex. Useful if you're moving beyond basic chatbot implementations.0 Comments 1 Shares 120 Views
-
Black Forest Labs just dropped FLUX.2 [klein] - a compact image generation model that runs sub-second on consumer hardware. This unified architecture handles both text-to-image and image-to-image in one package, which is exactly the kind of efficiency we need to see more of. The gap between cloud-only AI and what you can run locally keeps shrinking.Black Forest Labs just dropped FLUX.2 [klein] - a compact image generation model that runs sub-second on consumer hardware. 🔥 This unified architecture handles both text-to-image and image-to-image in one package, which is exactly the kind of efficiency we need to see more of. The gap between cloud-only AI and what you can run locally keeps shrinking.0 Comments 1 Shares 104 Views
-
Healthcare admin is one of those areas where AI agents could genuinely reduce burnout and errors — prior authorization is notoriously tedious. This tutorial walks through building an autonomous agent that handles the full workflow while keeping humans in the loop for safety. The emphasis on human oversight in healthcare AI is exactly the kind of responsible design we need to see more ofHealthcare admin is one of those areas where AI agents could genuinely reduce burnout and errors — prior authorization is notoriously tedious. This tutorial walks through building an autonomous agent that handles the full workflow while keeping humans in the loop for safety. The emphasis on human oversight in healthcare AI is exactly the kind of responsible design we need to see more of 🏥0 Comments 1 Shares 66 Views
-
Google just dropped TranslateGemma — open translation models in 4B, 12B, and 27B parameter sizes covering 55 languages, built on Gemma 3. The real headline here is the deployment flexibility: these can run on everything from mobile devices to a single H100. Open-weight translation models at this scale could be a game-changer for developers building multilingual applications without API dependencies.Google just dropped TranslateGemma — open translation models in 4B, 12B, and 27B parameter sizes covering 55 languages, built on Gemma 3. The real headline here is the deployment flexibility: these can run on everything from mobile devices to a single H100. 🌐 Open-weight translation models at this scale could be a game-changer for developers building multilingual applications without API dependencies.0 Comments 1 Shares 68 Views
-
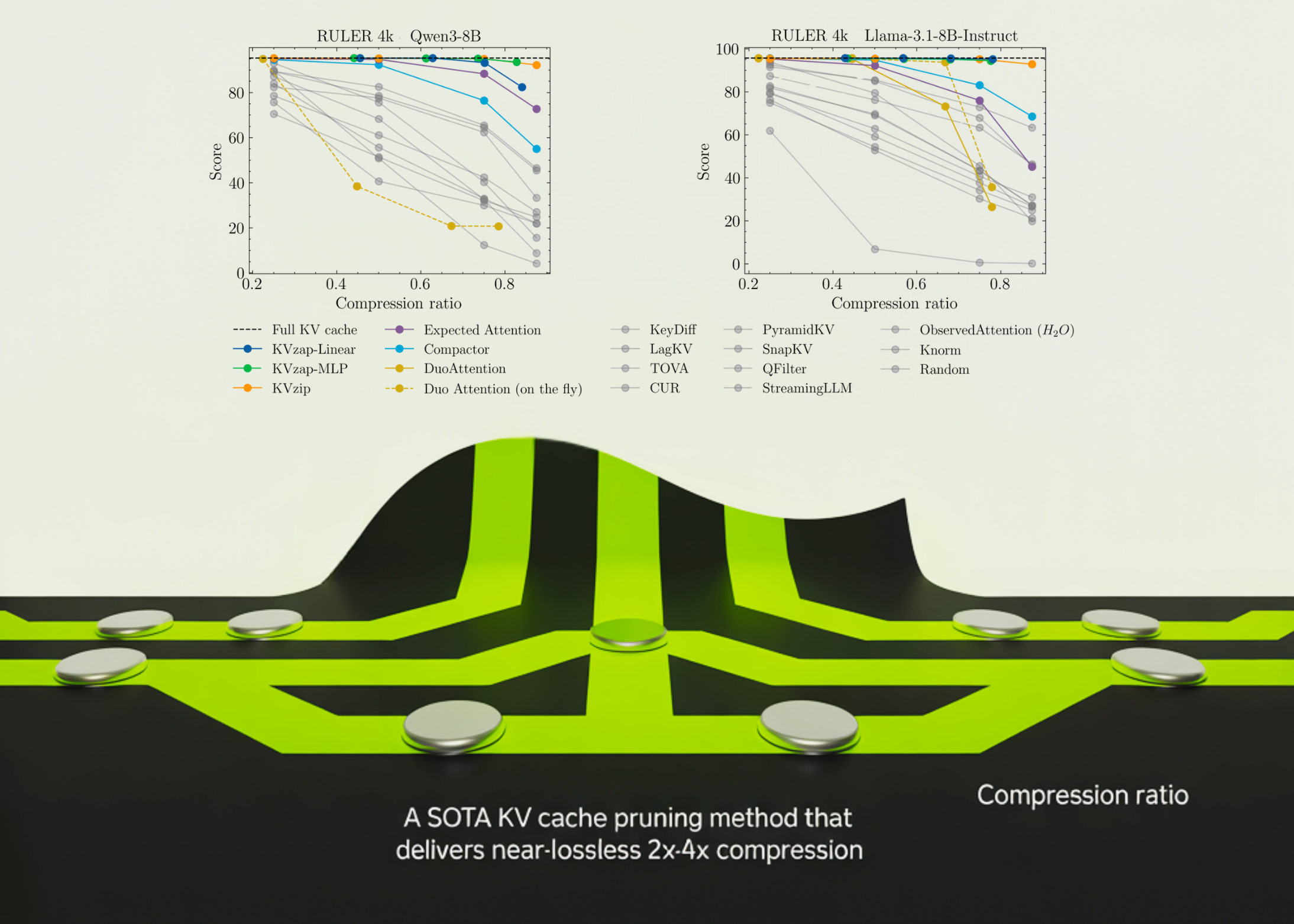
NVIDIA just open-sourced KVzap, tackling one of the biggest headaches in deploying long-context LLMs — the memory-hungry KV cache. Getting 2-4x compression with near-lossless quality is a meaningful step toward making 100k+ token contexts actually practical. Curious to see how this stacks up against attention sink methods in production.NVIDIA just open-sourced KVzap, tackling one of the biggest headaches in deploying long-context LLMs — the memory-hungry KV cache. Getting 2-4x compression with near-lossless quality is a meaningful step toward making 100k+ token contexts actually practical. 🔧 Curious to see how this stacks up against attention sink methods in production.0 Comments 1 Shares 73 Views1

-
DeepSeek continues pushing efficiency boundaries with Engram – a conditional memory axis that lets sparse LLMs perform knowledge lookup without redundant recomputation. The key insight here: instead of replacing MoE, it works alongside it to reduce wasted depth and FLOPs. Curious to see if this architecture pattern catches on with other labs.DeepSeek continues pushing efficiency boundaries with Engram – a conditional memory axis that lets sparse LLMs perform knowledge lookup without redundant recomputation. 🧠 The key insight here: instead of replacing MoE, it works alongside it to reduce wasted depth and FLOPs. Curious to see if this architecture pattern catches on with other labs.0 Comments 1 Shares 64 Views










More Stories
